
Every now and then, I see new Gopher clients and sites popping up. And that’s great—we’re keeping this protocol alive for the next generation. However, I can’t help but think some of the methods of doing so is restrictive, only getting the “Gopher is a list of links” part.
Back when NCSA Mosaic came out, it supported the Gopher protocol by generating an HTML equivalent to each menu. The idea of that makes sense; I mean, you already have a web browser that technically is capable of displaying the same content. This behavior has been replicated many times by the major web browsers and fellow gophermeisters over time when implementing Gopher support to client software.
The problem with that, however, is that you miss out on the potential that Gopher menus have to be not just a list of links. It’s important to understand that Gopher is as much a file transfer protocol as, say, anonymous FTP is, and it would make an amount of sense to implement it similarly. There are two main features that I would like to see more often in modern Gopher clients that stem from this and I will talk about them now. Get the popcorn.
First, we have directory trees. When you use Gopher, you are connecting to another computer’s file system. Unlike hypertext, it is clear what type of item Gopher menus will lead to. It’s easy to pick out what items in a Gopher menu lead to directories: the type is always 1. Just lay those out in an easy to navigate tree view at the side, and expand the tree as you load more directories. WSGopher32 did this very well, with the exception of taking out directory selectors from the menu entirely, which is an issue because selectors all pulled out of context. Take this capture of Floodgap for example:

One more recent Gopher client that has done this is Little Gopher Client. It’s made in Lazarus and gives you a general idea on what it could be like on modern systems. The typical issue is when there are backlinks on Gopher menus. If memory serves, both of these display backlinks which take up unnecessary space and can lead to the infinite nesting of doom. Frankly, however, this issue can be solved very easily: when an item shows up with a location that is already in the tree in some form, the tree node could either change in appearance and be used as an alias or (hopefully optionally) be cut altogether. When using a tree view, I’d recommend keeping the main menu view intact, especially when cutting items since it is especially important that all of a Gopher menu’s items are displayed with context.

While still on the topic of trees, there’s another way Gopher clients used to do it, which still used one view. This is the method used by Cyberdog and to an extent OverbiteFF. With Cyberdog, you could expand directory selectors into a new tree view. It’s a neat way of doing things.
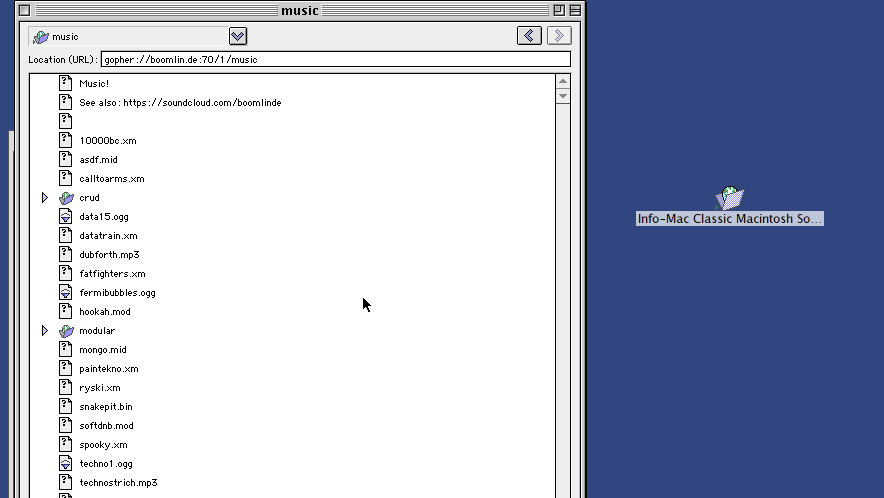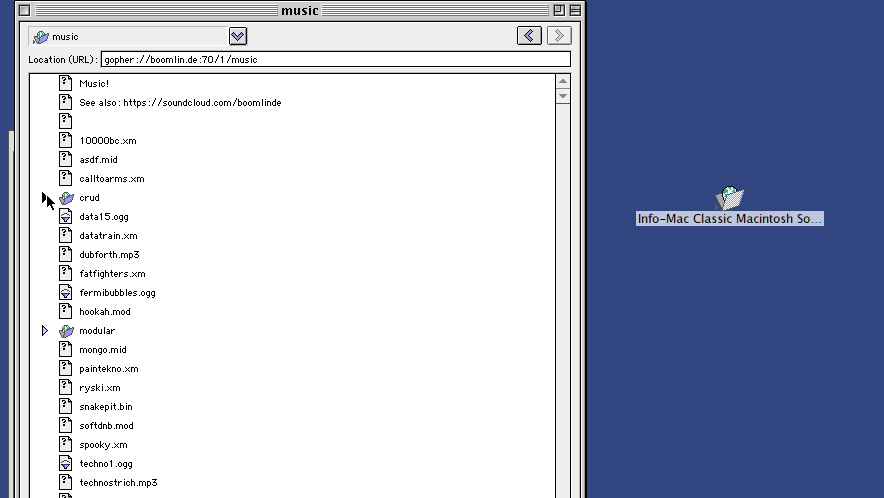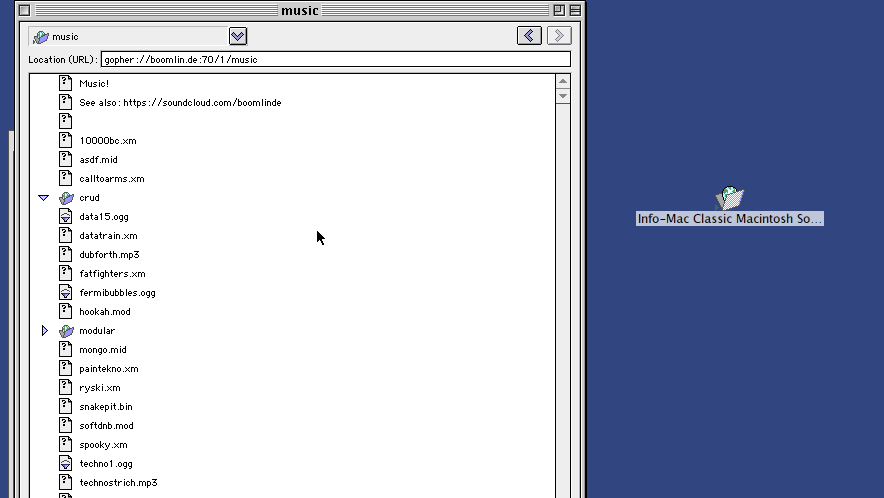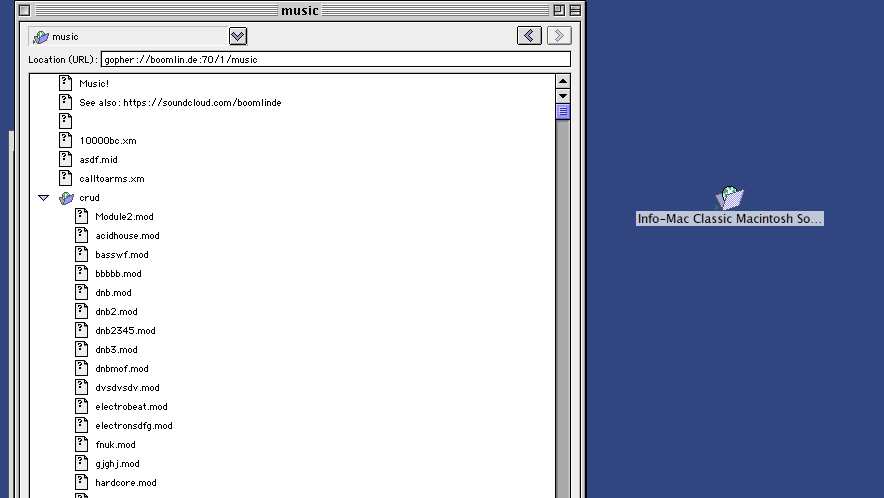
Netscape 6 did this similarly, actually, but its main shortcoming was the pretty ridiculous decision to cut out information selectors instead of leaving them be.

Second, there’s desktop integration. Think about it; the Web is very limited in this sense. You can’t drag a picture out of a web page onto your desktop, at least not in modern browsers, and you can’t select or download multiple links at the same time without extensions (which are getting more and more limited by the day). Cyberdog provides an excellent example of how this can be done well with Gopher. You can select multiple files at once, and drag them all into a folder in the Finder or your desktop to batch download them. Dragging directories onto your desktop would make aliases.

As an aside, Cyberdog also displayed this drag and drop behavior with a feature called Notebooks, which is basically its equivalent to the modern bookmark system many browsers have (that I can hardly use in an organized fashion). Dragging items into the notebook make bookmarks that can be sorted. Cyberdog notebooks could store links from all of the Internet protocols it supported. The notion that Gopher menus are just a list of hypertext links restricts it from so many opportunities.
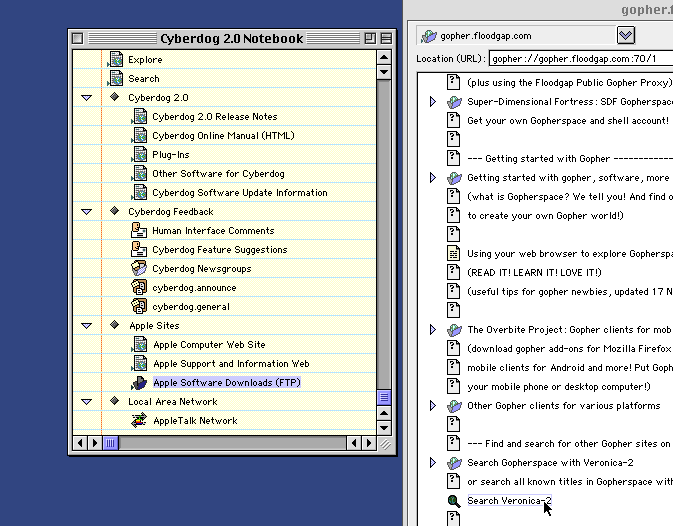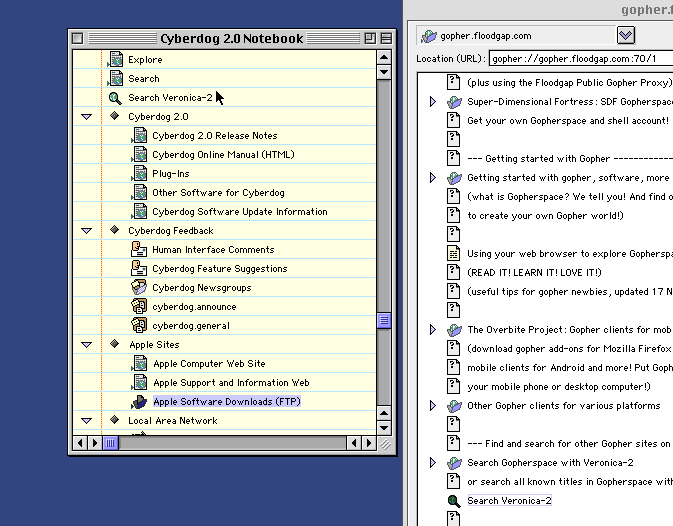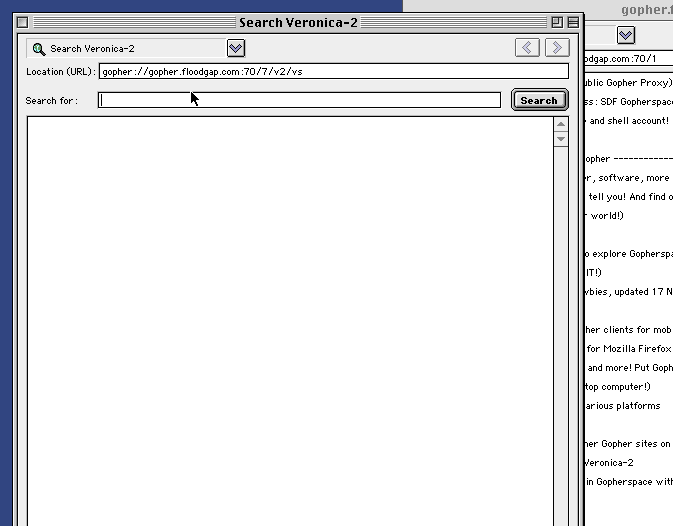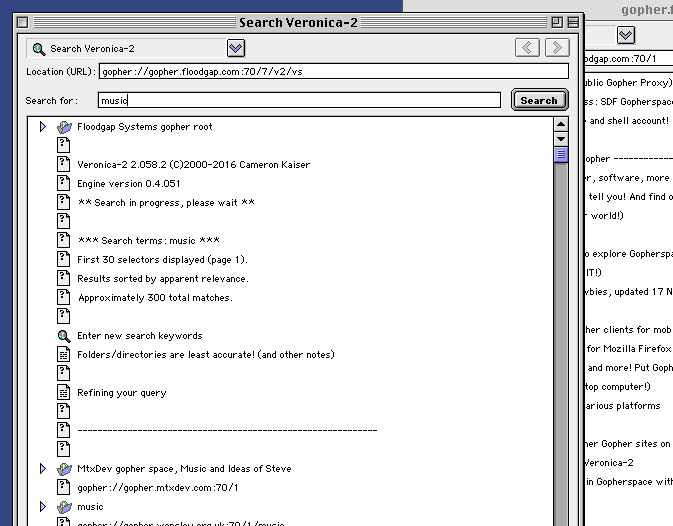
These are very unique uses of Gopher that haven’t been taken advantage of nearly as much in recent times. There is still an infinite amount of potential for this protocol, much of which hasn’t been quite realized yet. I’m hopeful with the upbringing of new Gopher software that hopefully going further we can have a more intuitive and widespread Gopher for all of us.
Pingback: Spring 2019 drafts | dcb's 32-bit Patio